文章
分析爬网数据时
不要低估先进的过滤功能
在帮助客户处理主要算法更新/排除技术性SEO问题等问题的同时,经常审核大型网站。这几乎总是需要一个彻底的网站抓取(通常在一个接触的生命周期中几次爬行)。搜索可能会在网站上发生破坏,切割和抓取数据集中分析非常重要。
通过良好的数据过滤,您通常会出现可能导致严重问题的页面类型或子域。一旦出现,您可以大量分析这些领域,以更好地了解核心问题,然后解决需要修复的内容。
从爬虫的角度来看,我已经在搜索引擎上覆盖了我最喜欢的DeepCrawl和Screaming Frog上了。两者都是出色的工具,我通常使用DeepCrawl进行企业爬网,同时使用Screaming Frog进行外科手术抓取。在我看来,使用DeepCrawl和Screaming Frog的组合是杀手,并且我经常在使用两个工具时说1 + 1 = 3。
下面我将介绍几个在两个工具中使用过滤的示例,以便您能够了解我所指的内容。通过过滤抓取数据,您将可以将网站的特定区域进行隔离和表示,以便进一步分析。一旦你开始这样做之后,你就会磁环这样的方式的。
可索引页面
我们从一个基本但是很重要的过滤器开始。内容质量在多个层面上可能是非常有问题的,您绝对希望确保这些问题不存在于可索引页面上。当Google从质量角度对网站进行评估时,需要考虑整个网站。
因此,当您在网站上出现问题时,可以通过可索引的URL过滤该列表,以便将您的分析集中在可能会损害网站质量的网页上。而且并不是因为没有被索引而忽略其他的URL!你也应该绝对照顾他们。请记住,用户正在与这些页面进行交互。在挖掘内容时,可以隔离编入索引的页面。
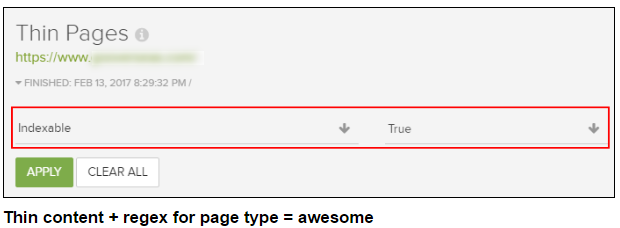
对于那些喜欢正则表达式的人,这里有一个好消息。DeepCrawl支持高级过滤的正则表达式。 因此,您可以选择一个过滤器,然后选择“匹配正则表达式”或“不匹配正则表达式”来执行一些手术过滤。 顺便说一句,真的有一个“不匹配正则表达式”过滤器来开始删除要排除的URL,包括。
例如,让我们通过使用管道字符来简单地组合过滤器中的三个不同的目录。管道字符在正则表达式中表示“或”。
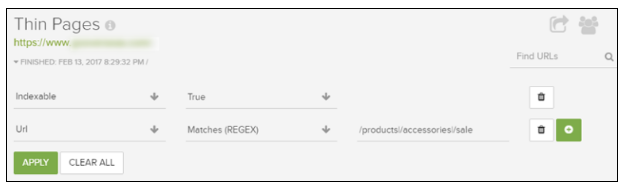
或者,如何排除特定目录,然后专注于仅以两个或三个字符结尾的URL(这是在特定审计期间从内容角度认为是有问题的URL的实际示例):
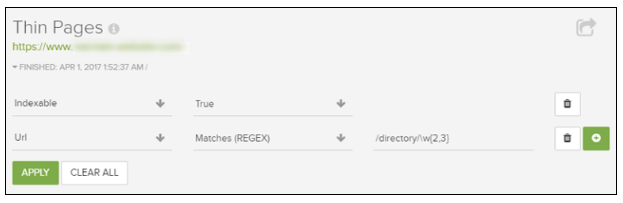
或者,如何将页面类型的正则表达式与字数混合,以通过页面类型或目录来识别真正的薄页面? 这就是为什么过滤功能非常强大(节省时间)。

你得到的照片。您可以包含或排除您想要的任何类型的网址或模式。您可以对过滤器进行分层以磨练报告。对于大规模抓取进行聚焦是非常惊人的。
规范问题:响应首部
去年,有一篇关于如何检查X-Robots-Tag以解决潜在危险的机器人指令(因为它们可以通过标题响应传递,并且肉眼看不见)的帖子。在大型网站上,这可能是非常险恶的,因为当表面看起来很好时,页面可能会被错误地标记出来。
那么你也可以通过标题响应来设置rel规范。这可能会导致一些奇怪的问题(如果您不知道如何设置相关规范,可能会让您感到疯狂)。在某些情况下,您可以使用多个标准标签(一个通过标题响应)并在html中设置一个)。当这种情况发生时,Google可以忽略所有规范的标签,如他们的博文中解释的关于rel规范的常见错误。
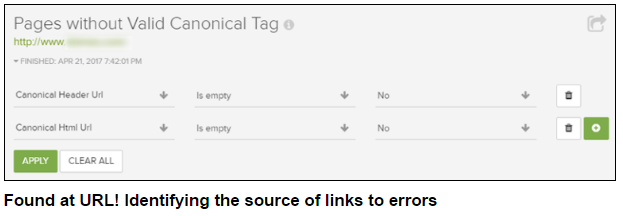
通过检查“没有有效的规范标签的页面”报告,然后通过rel相关的规范标题URL和rel规范的html URL进行过滤,可以显示所有具有此问题的URL。然后,您可以挖掘开发团队,以确定为什么发生在代码方面。
在大规模爬行(如404s,500s和其他)中,您无疑会遇到爬网错误。只是知道返回错误的URL往往不够好。您真的需要跟踪网站上链接的位置。
你想要解决大规模的问题,而不仅仅是一次性的。为此,请从任何抓取错误报告(或非200报告)中的“发现”URL过滤。然后,您可以使用正则表达式来表达页面类型和/或可能链接到返回爬网错误的页面的目录。
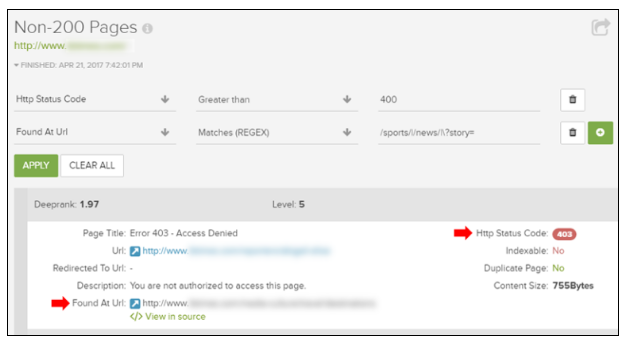
检查AMP URL:rel链接
使用加速移动页面(AMP)?要仔细检查您通过html中rel = amphtml引用的URL,您可以检查“所有rel链接”报告,并通过amphtml进行过滤。然后,您可以为“URL到”应用另一个过滤器,以确保这些是正在引用的真正的扩展名。再次,这只是一个简单的例子,说明如何过滤可以揭示坐在表面下面的险恶问题。
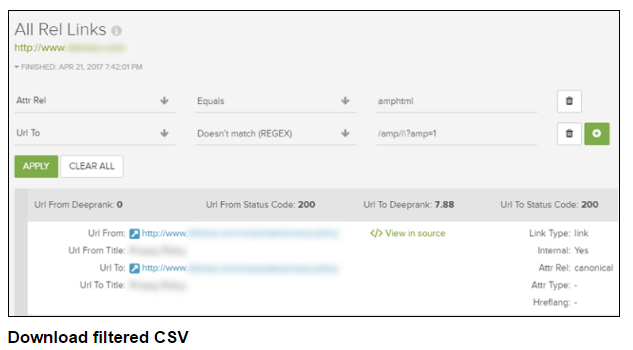
在DeepCrawl中分析爬网数据时,我提供了几个示例,您可以使用高级筛选方式进行操作。 但是当您要导出该数据时呢?由于您做了这么好的工作筛选,您绝对不想在导出时丢失已过滤的数据。
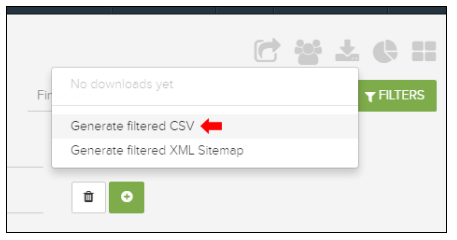
因此,DeepCrawl具有“生成已过滤的CSV”功能的强大选项。通过使用此功能,您可以轻松地导出过滤的数据与整个enchilada。然后,您可以进一步分析Excel或发送给您的团队和/或客户。
Screaming Frog过滤
对于Screaming Frog,过滤器不是很强大,但您仍然可以在UI中过滤数据。许多人不知道这一点,但在搜索框中支持正则表达式。因此,您可以使用DeepCrawl(或其他位置)中使用的任何正则表达式,以便在尖叫青蛙中按报告类型过滤网址。
例如,检查响应代码并希望按目录快速检查这些URL?然后使用管道字符来包含特定的页面类型或目录(或模式)。您会看到基于正则表达式的报告更改。
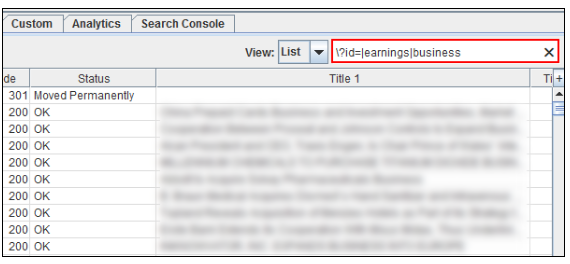
您可以利用预过滤的报告,然后对自己的过滤进行分层。 例如,您可以检查具有较长标题的页面,然后使用正则表达式过滤以开始浮雕特定页面类型或模式。
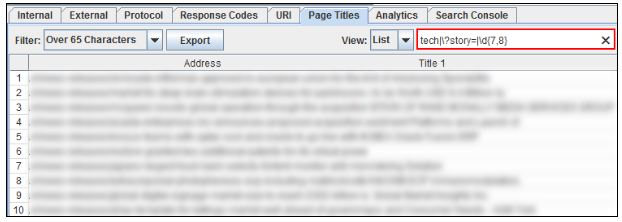
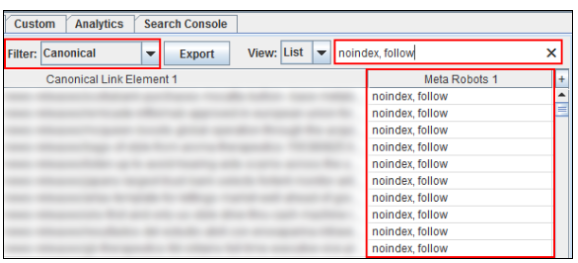
过滤器适用于所有列! 因此,您可以对该特定报告中列出的任何列使用正则表达式。 例如,从包含规范网址标记的所有网址开始,然后我使用“noindex”表达包含元漫游标签的网址。
如果一个URL是没有索引的,那么它不应该包含规范的URL标签(这两个都相互抵触)。 Rel规范告诉引擎哪些是索引的首选URL,而使用noindex的元机器人标签告诉引擎不对URL进行索引。这是没有意义的。 这只是一个简单的例子,您可以在Screaming Frog中过滤。 注意:Screaming Frog有一个“规范错误”报告,但这是一个快速的方式来过滤UI中的表面问题。
从导出的角度来看,不幸的是不能仅导出已过滤的数据。但是,您可以快速将过滤的数据复制并粘贴到Excel中。谁知道,也许聪明的人在Screaming Frog将建立一个“导出过滤的数据”选项。
总结
花费大量时间抓取网站和分析抓取数据,不能不强调过滤的力量。当您添加正则表达式支持时,您可以真正开始对数据进行切片和切割,以便潜在的问题出现。而且您可能越快遇到问题,您可以更快地解决这些问题。这对于具有数万,数十万甚至数百万页的大型网站尤其重要。所以继续...过滤掉。
转载请注明出处,全球贸易通-外贸电商学院http://edu.bossgoo.com/marketing/seo/341.html
上一篇: 5个你需要掌握的大规模SEO和内容转换 下一篇: 如何优化语音搜索
联系电话:400-099-0905
总机:0574-87642848、87642955
传真:0574-87910666
E-mail:agent@bossgoo.com
地址:浙江省宁波国家高新区宁波市软件产业园(创苑路750号)D座第6层

马上关注

